

中国古人追求的梦想是“拓地三千里,往返速若飞”,现代人类衣食住行的理想境界,也无非是“健康、快乐、富足、平安”。然而,从UN的统计数据可以看到,全球每年道路交通事故都约有5000万人伤, 125万人亡,经济损失可以高达约1.85万亿美元,而94%交通事故均来自可以避免的人为因素,且90%发生在中低收入的国家。研究表明,将有效预警提前1.9秒,事故率可下降90%,而提前2.7秒,事故率可下降95%,所以AI算法的感知认知领域的技术进展推动了辅助ADAS以及自动驾驶ADS技术的行业落地也是势在必然的。2021年统计数据表明,一个US司机在自然驾驶环境NDE下每英里的车祸发生平均概率约在百万分之一的水平。而2021年US加州自动驾驶车辆AVs最好的disengagement rate也只能做到十万分之一,这一定程度表明AVs的安全性能估计比人类明显要差一个数量级,虽然可以适应仿真和简单的不密集的约束真实场景,但仍难以应对城市的复杂道路交通场景。场景适应能力问题,以及最核心的安全差异问题也就是所谓“Long-Tail Challenge长尾挑战”,依旧是ADS当前待解决的最大难题之一。
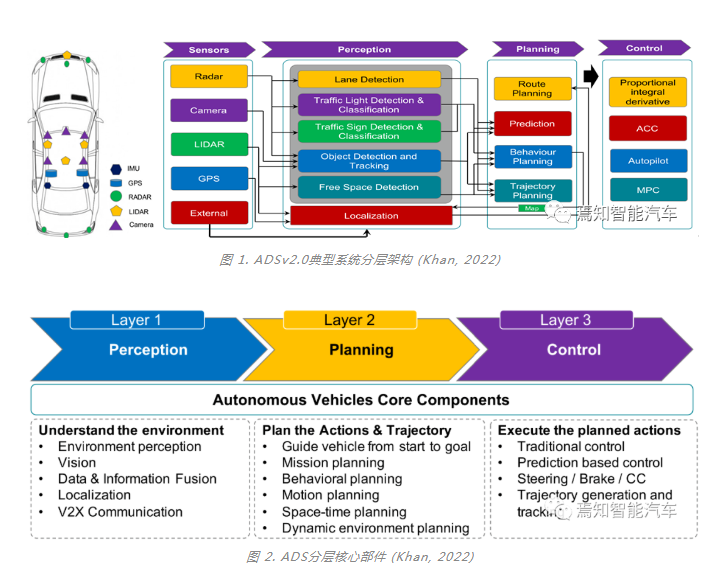
ADS算法的典型系统分层架构如图1和图2所示,目前已经从多模数据结构化+决策层后融合ADSv1.0演进到了一个全新的多模感知与融合推理的特征级前融合ADSv2.0阶段。如上文所述,ADS面临的挑战具体体现在:
1)能够在统一空间支持多模传感器感知融合与多任务共享,在提升有限算力的计算效率的同时,确保算法模型在信息提取中对极端恶劣场景(雨雪雾、低照度、高度遮挡、传感器部分失效、主动或被动场景攻击等)的泛化感知能力,降低对标注数据和高清地图的过度依赖;
2)预测与规划联合建模,离线与在线学习相结合,监督与自监督学习相结合,从而能够处理不确定性下的安全行驶与有效决策,提供认知决策行为的可解释问题,通过持续学习解决新场景问题。
01
ADS场景适应能力的挑战
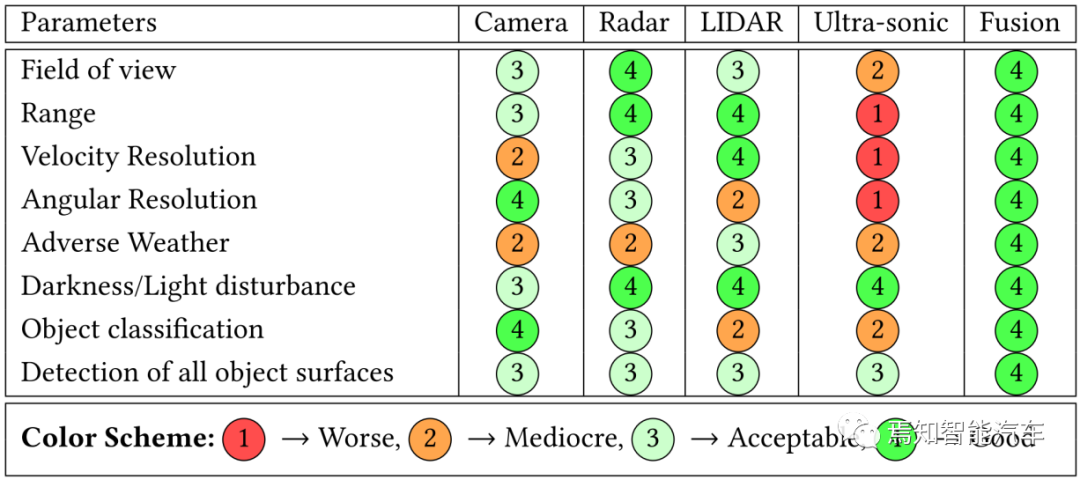
图 3. ADS场景适应能力问题 (Khan, 2022)
如图3所示,ADS部署的传感器在极端恶劣场景(雨雪雾、低照度、高度遮挡、传感器部分失效、主动或被动场景攻击等)的影响程度是不一样的。所以传感器组合应用可以来解决单传感器的感知能力不足问题,常用的几种组合是:Camera+LIDAR; Radar(3D, 4D)+Camera+LIDAR(LD, HD);Radar+Camera。统计数据表明Radar+Camera是最常见组合。ADS传感器特性总结如下
Camera:可以提供360环视和远距前后视角的环境语义表征,但需要一个照明环境,单目和多目Camera可以提供一定程度的目标深度信息;受恶劣场景影响严重;镜头脏污会严重影响图像质量。
LIDAR:可以提供场景的空间信息;但难以检测有反光效应的或者透明的物体;当雨速高于40 mm/hr 到95 mm/hr,信号反射密度严重损失并产生雨枕现象;大雪天气下可视距离缩短并产生反射干扰波形;浓雾场景会产生鬼影现象;温差会产生额外时间延迟
Radar:对周围车辆检测准确率高,可以提供目标的速度信息,4D Radar还可以提供目标高度的可靠信息;不适合做小目标检测;大雨浓雾和暴风雪会产生接收信号强衰减和斑点噪声,总体对环境的适应性高。
AVs使用体验数据显示,在暴风雨雪天气,车辆的控制由于打滑和oversteering等原因,目前是远低于用户期望的。
02
ADS长尾问题的挑战
“长尾问题”没有一个很明确的定义,一般指AVs即使经历了交通公路百万公里数的路况测试,对每个AI算法模块而言,包括感知层和决策层(预测+规划),仍不能完全覆盖各种各样的低概率安全至关重要的复合驾驶场景,即所谓的“Curse of Rarity (CoR)稀缺问题”。如何定义和分析这些稀有场景,可以有助于更好理解算法性能的提升,从而加速安全可靠的ADS解决方案的开发与部署。
对于大部分视觉任务而言,问题复杂度增加,对应维度也在增加,意味着数据在特征空间更加稀疏,为了一个可靠的结果,数据需求会随维度增加而指数增长,而性能只可能线性增长,R. Bellman统一定义这类问题为“Curse of Dimensionality (CoD)高维问题”。ADS领域的CoD高维问题显然来自上述所提的各类天气状况,道路基建,人车混杂,城市乡村各类路况,道路设施(高速,路口,转盘,隧道,高架桥),人车交互,车车交互等。针对CoD问题,深度学习DL算法在ADS领域确实带来了很多长足的进展,包括:
多模感知:主要是针对Camera/LiDAR/Radar海量数据流进行特征提取,DL网络主流趋势是卷积CNN或者贝叶斯NN+Transformer的组合架构,在统一的特征空间实现多模感知,特征融合共享以及多任务来提升算力的整体效率与安全可靠的环境感知能力。
融合推理:主要是基于模型与基于数据的双学习模式,DL网络主流趋势是基于目标交互GNN或基于统计模型的贝叶斯RL学习或On-Policy应急学习,实现ADS安全可信的预测规划类决策与控制。
对于上述CoD高维问题的解决,可以简单分成两种应用方式:
1.感知层的特征高维提取和降维融合重建:DNN网络多采用梯度下降Gradient Descent (GD)来做网络参数调优,对应的视觉任务包括3D目标检测跟踪,交通路标检测分类、场景与可驾驶区域分割,分道线检测或分割等,AI模型多采用CNN,Transformer,Bayesian NN,RNN, GNN等;
2.决策层的策略(decision-making policy)学习:DNN多采用Policy Gradient (PG)理论、Bootstrapping、Monte Carlo Tree Search来做优化策略,将高维变量空间转换到NN的参数空间,对应的视觉任务包括目标行为建模与运动轨迹预测、运动规划与定位控制等。AI模型多采用Deep Reinforcement Learning (DRL),Graph Convolution Network (GCN), Transformer, 结合贝叶斯学习、模仿学习Imitation Learning (IL)、Inverse RL、Off-Policy和On-Policy应急学习等;
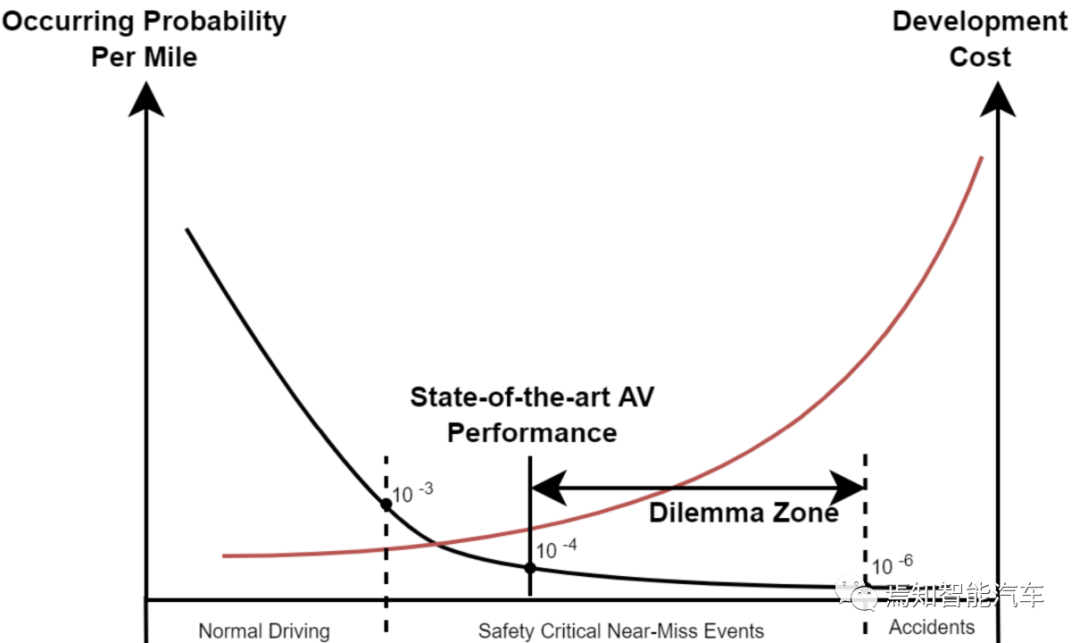
图 4. ADS中CoR问题的呈现图 (Khan, 2022)
4所示,上述几类方法可以部分解决CoR稀缺问题,但在机器人、ADS领域的一个关键挑战是系统安全性能的保证。一个解决的思路是采用仿真来产生上述所提的大量稀少的安全事件场景,但仍然远远不够,原因在于多数仿真环境采用手工设计的规则很难模仿现实驾驶场景的高复杂性与不确定性,安全相关的真实事件数据非常难以采集,实际路况中人车交互和车车交互也很难建模,安全度量和评估也同样异常艰难。从AI算法角度,可以在仿真数据基础上继续结合Importance Sampling和Importance Splitting方法,Importance Sampling方法可以根据输入的概率分布来对输出的Likelihood Ratio释然比进行加权来产生无偏置的估计,这只适合简单的场景。Importance Splitting方法强激励的通道可以继续分解,可以将稀有事件的估计分解成条件概率分布序列从而减少估计方差,但人工设置的阈值选取是一个挑战,也很难评估Policy空间的性能敏感性,尤其是针对near-miss事件和交通事故等各类不确定性。
03
ADS-RL安全学习的挑战
对于ADS的决策层算法而言,最早采用的基于手工设计的规则的方法,应用场景受限难以应对现实驾驶场景的高复杂性与不确定性,其典型案例是开源自动驾驶系统Autoware和仿真平台CARMA,采用有限状态机来产生车辆轨迹,为了确保AVs行驶安全,在高复杂度交互场景会产生车辆减速或停车现象即所谓的”Freezing Robot”问题。工业界采用的基于数据的监督学习的方法,仍然难以解决CoR和CoD中数据总量和数据不平衡的问题,现有的真实驾驶里程标注数据总量,估计只有期望数据量的1%以下。
第三类最有希望的DRL方法是一种模仿动物学习行为的自学习方法,通过状态State不断地与环境的行为交互Action带来的奖励Reward积累来寻求最优策略Policy,最大化未来累计奖励的一个随机过程,来应对不确定性。按照最优策略的获得方式,可以将RL分成间接式Indirect RL和直接式Direct RL两种:
Indirect RL:可以分成Policy Iteration和Value Iteration两种,其的基本原理是通过求解问题的最优性条件得到最优策略,针对连续时间问题,多采用哈密顿-雅可比-贝尔曼方程(HJB equation)求解;针对离散时间问题,采用贝尔曼方程(Bellman equation)求解
算法案例:Deep Q-Learning, DQN, D3QN, A3C, GAE, DDQN
Direct RL:其最优策略是寻找最大化目标函数的参数化策略,将最优控制问题看成一个优化问题,采用数值优化方法进行求解,可以采用一阶优化方法,即策略梯度Policy Gradient法,它沿着目标函数上升的梯度方向,不断地更新策略参数,直到找到最优解,最新的策略多采用将ADS行驶安全也做为一个约束项
算法案例:TRPO,PPO, DPG, DDPG
DRL采用的Policy Gradient方法,其目标函数可以表示为

采用DRL学习的方法,由于CoR和CoD问题,同样存在稀疏奖励Reward问题和Policy Gradient估计的方差过大等瓶颈问题。
在数据比较充分的情况下,深度模仿学习Deep IL通过行为克隆、直接策略学习、和Inverse IL来模仿人类的驾驶行为,这种监督模式的知识学习方式对大多数场景是比较有效的,而且学习效率高于DRL, 但缺陷同时也非常明显,其一是模仿学习永远难以超越人类的驾驶水平,其二是涉及交通安全的场景,CoR问题依旧存在,存在数据集偏置不平衡和实验与真实场景不匹配“Covariate Shift”的问题。现在一种比较通用的方法是把Deep IL与DRL相结合来提升学习效率。这里值得一提是将图神经网络Graph attention-based Network (GAT)与DRL结合,利用自关注GAT来对异构交通信息(路面结构和车辆状态)进行编码和对车辆 交互进行隐形建模,DRL的策略网络综合了基于像素的和基于状态的知识信息来无监督训练AVs来适应动态变化的城市交通场景,减少了对标注数据的依赖。
04
Deep Safe-RL的挑战
Deep Safe RL做为DRL的一种,通过一些先验假定(例如受限扰动集)与安全约束,来提升安全性能保证。Safe-RL通常可以建模成受限的马尔可夫决策过程CMDP,对应的可行策略集需要满足安全约束边界,优化目标是在累计约束下提供最大奖励性能和用最小的代价值来满足安全。太约束的先验假定会导致部署时决策过于保守,反之则容易导致车祸发生,而且这些先验约束会与场景相关,仍难以应对不确定性的超级复杂场景,尤其是CoR和CoD问题的组合场景。目前对safe multi-agent RL的研究也处在刚起步阶段。
Safety Under Uncertainty: 对ADS决策来说,知道我们什么时段不知道什么非常重要,同时我们也需要识别决策是否是确定可行的,一种常用的做法是对不同的路径规划提供安全性的概率估计来帮助决策。决策的确定性分析与可解释性,也有助于开发与验证工作。
05
CoR稀缺问题的挑战
涉及交通安全的事件场景数据是非常稀缺的。假定上亿英里里程数可能碰到一次AVs的致命事件,需要上万亿英里的里程数估计才能积累足够的数据。从工程实践来看是非常不现实的,虽然2022已有几个国家先后开通了ADS L4车辆上路的法规,但这个僵局严重影响了AVs安全性能的提升和部署进程。一个可行的方案是通过收集人驾驶的车辆数据,例如US交通部的统计,每年全国有3万亿英里的里程数累计,其中包括6百万次车祸,2百万人受伤,3万人致命伤亡事件。避开数据采集的隐私问题不谈,这类自然驾驶环境NDE海量车辆轨迹数据,可以有助于建立高保真NDE模型,从而通过仿真环境来构建大量合成数据,这样的思路在过去对其它行业感知类视觉任务已经证明是非常行之有效的。

图 5. ADS 协同CAV的呈现图 (Khan, 2022)
业界第二种思路是将这类涉及交通安全事件的发生概率降低到人类可以接受或者可以忽略的水平。如图5所示,解决问题的途径包括协同CAV技术,即通过对道路基础设施部署大量的多模传感设备(Camera, LIDAR, Radar),通过 V2V,V2I(例如路边边缘计算设备RSD)和V2X通信技术来提供车车或者车路协同来实现知识与信息共享,有效解决单个AVs由于遮挡和有限视野问题产生的难决策的僵局。相对而言, 单AV的多摄像头、多模融合感知多任务共享,以及CAV(V2V,V2I)之间跨摄像头、跨模感知融合技术目前已经有非常明显的进展。
小样本数据问题,一直是业界的一个大难题。零样本或者小样本学习,持续学习或者终身学习,也一直是学术界的研究重点,从人类常识角度来说,也是可行的。人类的推理学习模式是两种的融合:从底往上推理(感知数据驱动建模)+由上往下推理(知识学习与认知期待驱动推理)。ADS在知识推理层面演进也应该能够解决CoR和CoD的综合难题。DL算法演进能够有效解决 CoD问题,稀有事件的仿真也许可以有效解决CoR问题,通过有限数据与数学物理模型的组合应用在液体动态力学有了一些长足进展,期待类似思路能够应用到ADS领域。
 Copyright © 2005-2021 网信安全世界版权所有
Copyright © 2005-2021 网信安全世界版权所有