

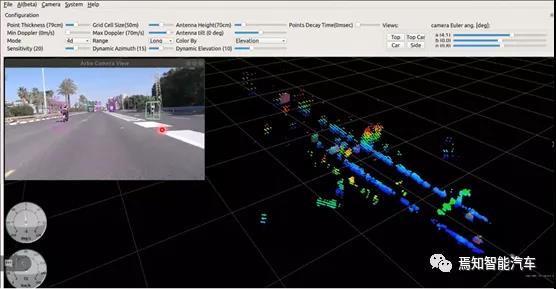
本文将针对性如上三个比较棘手且亟待解决的问题进行详细阐述,意在为开发者提供借鉴。
01 如何提升静止目标碰撞检测
从开发测试角度,我们已经收集了不少难解决或可能出现问题的场景。其中,对于静止目标的识别就是其中之一。从全视觉的角度出发,当前成型的自动驾驶产品都是基于单目或三目视觉来进行检测的。而这种检测方式有着天然无法改变的缺陷,由于该方式是基于深度学习的机器视觉,其表现为识别、分类、探测是放在同一个模块进行的,通常无法将其进行分割,也就是说,如果无法将目标分类classification,进而往往针对某些目标就无法进行有效探测recognition。这种漏识别就容易导致自动驾驶车辆发生碰撞。
为了很好的说明无法识别的原因,总结解决该类问题的方法这里我们需要重点说明下:第一种是训练数据集无法完全覆盖真实世界的全部目标;因为很多静止目标不一定是标准的车辆,甚至可能是异形车辆、落石、不规则施工标志灯,因此,在开发阶段训练的目标类型在很大程度上都无法用于真正的自动驾驶识别场景。
第二种是图像缺乏纹理特征,纹理特征包含多个像素点的区域中进行统计计算,常具有旋转不变性;对于噪声有较强的抵抗能力;因此,对于一些纹理较少的货车车厢、白墙等,通过视觉方式都是较难识别出来的。
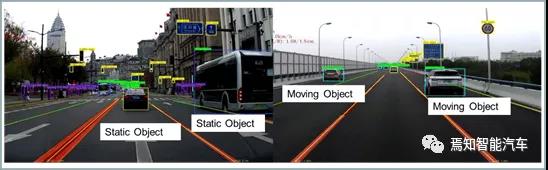
此外,这里需要解释一下为什么深度学习对静止目标无法做到很好的识别能力。因为深度学习中的机器视觉,特别是基于单目摄像头探测的机器视觉图像,会将所有静止目标当作背景加以剔除,从而可以很好的选出对视频理解过程重要的运动目标,这种方式不仅可以提升识别效率,也可以很好的降低编码码率。同时也为了防止误检测,也必须将运动目标和静止目标分开,如有些道路两侧停满汽车,运动目标的优先级自然高于静止目标,然后再去识别,通常是背景减除、三帧法或光流法,通常情况下这类识别算法需要耗费1-2秒时间,然而对于实时性要求较高的自动驾驶而言,这段时间就可能已经发生碰撞事故了。
因此,为了解决如上识别性能缺陷,就需要从根本原因上解决深度学习不足所带来的问题。机器视觉主要有两种学习匹配模式,一种是手工模型,一种就是深度学习,通常都是采用后者进行图像识别和分类。由于深度学习主要是通过分割再拟合,原则上它要遍历每一个像素,对训练好的模型做数十亿次的乘积累加并设置不同的权重值来做对比,区别于人类视觉,机器视觉是非整体性的。从本质上讲,深度学习是一种利用采集数据点,通过与已有数据库进行有效匹配,拟合出无限接近于实际的曲线函数,从而能够识别出期望被识别出来的环境目标,推断趋势并针对各类问题给出预测性结果。当然,曲线拟合在表示给定数据集时也存在一定风险,这就是拟合误差。具体来讲,算法可能无法识别数据的正常波动,最终为了拟合度而将噪音视为有效信息。因此想要真正解决对于这类异常环境目标的识别能力,仅仅依靠提升SOC芯片的AI加速器能力来解决是不明智的。因为AI加速器也仅仅是解决了MAC乘积累加计算模块的加速运算能力而已。
要想真正解决这类识别或匹配误差问题,下一代高性能自动驾驶系统通常采用多传感器融合的方式(毫米波雷达、激光雷达)或采用多目摄像头检测的方式进行优化。做过驾驶辅助系统开发的设计师应该清楚,对于依靠当前这代毫米波雷达由于对于金属物体十分敏感,在检测的物体过程中通常是规避因为误检而导致AEB的误触发的。因此,很多静止目标通常会被滤掉,同时,对于一些底盘较高的大货车或者特种操作车,往往会因为毫米波雷达高度问题导致检测不到目标而漏检。
需要利用传统办法(或称非深度学习算法)进行三位目标重建,通常这可以采用激光雷达或高分辨率4D毫米波雷达来进行点云重建或双目摄像头进行光流追踪来实现优化。对于基于激光雷达检测目标的方法,其原理是发射探测信号(激光束),然后将接收到的从目标反射回来的信号(目标回波)与发射信号进行比较,作适当处理后,来获得目标的有关信息,因此对于回波的点云匹配本身也是一种深度学习过程,只不过这个过程相对于弹幕图像识别的分割、匹配更快些。
双目视觉的方式对静态目标的检测是依赖视差图像来进行的,这种以来纯几何关系的视差图是可以较为精确的定位该静态目标位置的。很多时候单目视觉对于颠簸的路况、明暗对比非常强烈的路况、一些破损的路况中的远距离的物体,可以完成检测,但是三维恢复会存在很多不确定性。而立体相机可以与深度学习融合,将立体点云与图像的RGB信息以及纹理信息融合,有利于进行远距离目标的识别及3D测量。
深度学习可以更精细更稳定地检测常见的道路参与者,综合多种特征,有利于更远地发现道路参与者。而立体视觉则可以同时实现3D测量与基于点云检测全道路参与者,不受物体类型限制,不受安装位置与姿态限制,动态测距更加稳定,泛化能力更好。我们将立体视觉和深度学习结合起来,可以在更远的距离发现目标,同时能够利用立体视觉进行三维刻画。
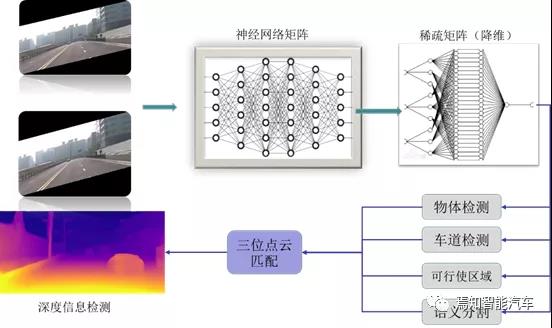
如上这些算法要么比较依赖CPU进行的逻辑运算包括实现卡尔曼滤波、平滑运算、梯度处理,要么依赖于GPU进行的图像深度学习处理。因此,下一代高阶自动驾驶域控系统需要具备很好的运算处理能力才就能确保其性能满足要求。
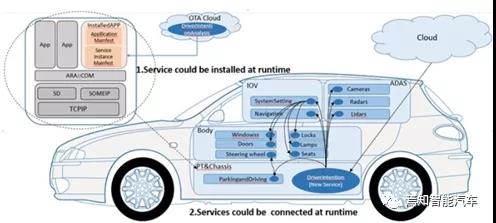
由此,基于SOA架构的设计高阶自动驾驶系统过程的重点在于实现如下功能:
1、服务通信标准化,即面向服务的通信
SOME/IP采用了RPC(Remote Procedure Call)机制,继承了“服务器-客户端”的模型。SOME/IP可以让客户端及时地找到服务端,并订阅其感兴趣的服务内容。客户端可以用“需求-响应”、“防火墙”的模型访问服务器所提供的服务,服务可以利用通知的方式推送给客户已经订阅的服务内容,这就基本解决了服务通信的问题。
然而,基于SOA架构的通信标准SOME/IP有两大缺陷:
a) 只定义了比较基础的规范,应用互操作性难以得到保证。
b) 难以应对大数据,高并发的场景。由于缺少对象序列化的能力,SOME/IP软件互操作性容易产生问题。SOME/IP不支持共享存储,基于广播的1对多通信,在自动驾驶场景下,性能可能成为问题。
2、SOA架构需要对服务进行划分,以服务重用、灵活重组为目的的服务划分,即面向服务的重用共享设计。
需要将SOA的系统-软件开发过程应用于整车功能逻辑的定义中去,架构会主导或者参与到需求开发、功能定义、功能实现、子系统设计、零部件设计等过程中去,面向服务的重用设计实现需要能够贯穿始终,并最终在功能实现的环节体现出来。
这里需要说明的是服务重用涉及到原有系统的切割和新系统的重建,随着规模的扩大和新功能的增加,以信息为基础的通信将会增长,如此以来,在预计之外的情况将开始经历一个重大的处理反应期,这个反应期可能造成数据访问延迟。而自动驾驶系统对于实时性要求极高,这也是SOA应用的最大局限性问题。
此外,对于SOA的软件实现而言,基于服务的软件架构搭建过程中需要充分考虑是否可承载和适配面向服务的通信设计及面向服务的重组实现问题。
总结
下一代高阶自动驾驶系统无非需要解决两类问题:我在哪儿,我要去哪儿?在这两类问题中一类依赖于地图定位,另一类依赖于导航控制。而基础架构是建立面向服务的设计能力,SOA的架构应运而生。如何在新架构下实现高阶自动驾驶系统功能的完美破局,将整体功能体验和性能提升到一个新高度是自动驾驶研发人需要重点突破的问题。无论从整体的开发方式,感知性能上都应该做到量变到质变的过程。这条路上还有很多亟待解决的问题,我们需要不断地个个解决之。
 Copyright © 2005-2021 网信安全世界版权所有
Copyright © 2005-2021 网信安全世界版权所有