

1 CodeQL简介
CodeQL是一种用于漏洞挖掘的代码审计工具,它可以根据已有的漏洞模型在庞大的代码库中找出相同类型的漏洞的变种,即可以帮助安全研究员或开发人员更快速精准地定位漏洞之处。它的前身是Semmle公司推出的代码分析工具SemmleQL,而Semmle公司在2019年被GitHub所收购,不久后GitHub便基于SemmleQL推出了CodeQL。由于其对于漏洞挖掘效率有着很大的提升,CodeQL工具被越来越多的研究员用来辅助进行漏洞挖掘。研究员根据特有的CodeQL语法编写CodeQL规则,这个规则实质上就是描述已有漏洞的特征,若在目标代码库中存在该特征的代码段就定位出来,方便进一步分析是否为漏洞,极大提高了效率。目前,CodeQL项目在GitHub网站里已经收获了5000多个Stars[1]。GitHub实验室也对高质量的CodeQL规则发起了奖金计划[2]。
CodeQL支持进行漏洞挖掘的语言包括:C/C++、C#、Go、Java、JavaScript、Python、Ruby[3]。其针对这些不同的语言有着不同的规则编写规范,本文主要针对C/C++的CodeQL的规则编写进行介绍,其他语言类似。
使用CodeQL进行漏洞挖掘的主要流程为:
1)使用CodeQL命令,根据目标源代码编译生成database,该database包含整个代码的AST树,CodeQL就是查询该database来进行漏洞发现的。
2)根据已知漏洞提炼出漏洞特征,并编写出CodeQL规则,该规则用以查询目标database找出类似的漏洞。在这一步有两个难点:一个是需要对漏洞进行总结归纳,提炼出漏洞特征,即是什么因素引发了漏洞;另一个是根据漏洞特征编写高质量的CodeQL规则,这里需要对CodeQL的规则的编写语法有着一定的熟悉。
3)根据CodeQL规则运行的结果进行代码审计,分析目标代码是否真正存在漏洞,确认漏洞的成因及触发条件。
本文从实际例子出发,介绍了CodeQL的环境搭建以及使用流程,希望能够为对该工具感兴趣的初学者提供一些入门的帮助。
2 CodeQL环境搭建
2.1 Visual Studio Code插件安装
CodeQL的规则编写以及规则运行是基于Visual Studio Code工具的,因此首先需要安装这个工具。可在[4]网址进行下载安装。该工具安装完成后,就可以进行CodeQL插件的安装,如下图所示。
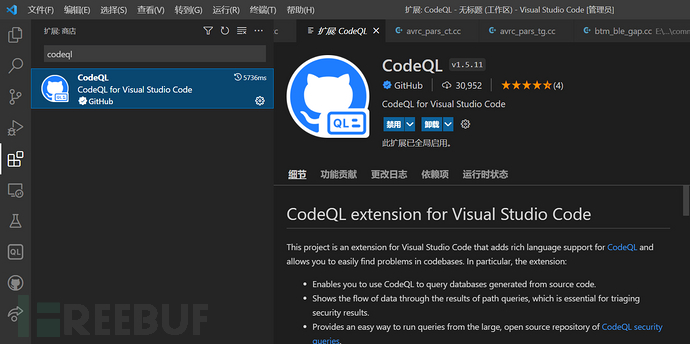
打开Visual Studio Code后,点击左边菜单栏的“扩展”按钮,在搜索框内填写“codeql”,右边出现CodeQL插件,添加“安装”按钮。
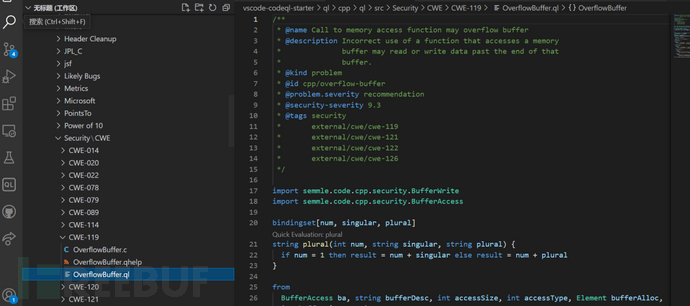
此外,需要在[5]网址下载一个codeql规则脚本案例库,根据其ReadMe,在Visual Studio Code中打开这个工程,可以用来学习规则编写。其中CWE-119会在4.2章节进行介绍。
2.2 解析引擎codeql-cli安装
解析引擎codeql-cli的安装主要是为了生成目标代码的database,既可以在Windows下也可以在Linux下安装。但由于本文主要针对的是C/C++的目标代码,在Windows时需要配置环境变量以及GCC编译环境,相对比较复杂,因此这里介绍在Linux系统下的安装。
首先,在[6]网站下载codeql-cli的liunx版本。
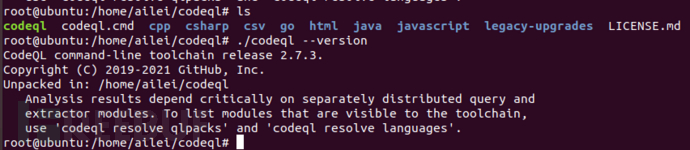
其次,把下载的文件放到Linux系统下进行解压,如Ubuntu虚拟机,获得的文件包含有codeql可执行文件,执行./codeql --version可以查看codeql版本号。可以把codeql执行文件添加到PATH目录或者在/usr/local/bin下面使用ln -s创建链接,以后可以直接使用codeql命令,不然的话,使用codeql命令时需要添加路径,如下图,可以在codeql目录下使用“./codeql”来运行codeql。
3 源代码database生成
CodeQL是一种白盒测试方法,它需要对目标代码进行处理,生成能够被CodeQL所使用进行查询的database。如下面这个例子。
1)编写一个有漏洞的c文件hello.c:
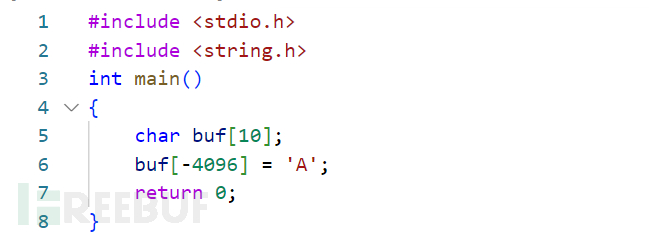
2)使用codeql命令生成database:
codeql database create ./hello-db --language=cpp -c "gcc hello.c -o hello"

![]()
该命令具体表示的含义可以由以下命令进行查看:
codeql database create --help
3)在生成的hello-db文件夹中,src.zip就是所有编译过的c/c++文件,可以解压对照是否是自己预想的目标代码;log目录保存的是database生成过程中的日志信息,若有报错也会在这里记录;db-cpp目录就是Visual Studio Code工具所需的目录,可以把其导入到Visual Studio Code工具中:把整个hello-db目录拷贝到Windows系统,打开Visual Studio Code工具后,在左边侧边栏选择CodeQL,在database中选择“从文件夹导入”,然后选择hello-db目录下的db-cpp。如下图所示。
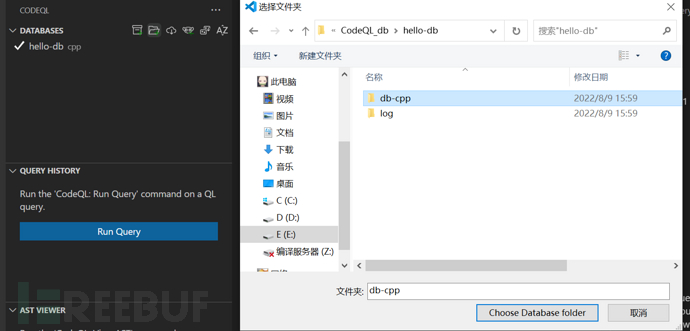
4)导入成功后会自动选择该database,编写CodeQL规则针对的目标代码就是该选中的database。对于如何编写规则来发现漏洞会在后面第4章介绍。
同理,针对一些大型项目,其database生成和上面所讲的类似,只不过codeql命令稍微复杂些,这里,针对AOSP的蓝牙模块进行了举例。
a)首先,需要设置环境变量export ALLOW_NINJA_ENV=1,确保database生成过程中覆盖所需的目标源码文件。
b)其次,若是已经编译过AOSP的话,需要在源码根目录下删除out文件夹:rm -rf ./out。
c)然后,针对目标模块,需要找到该模块的模块名称,蓝牙模块名在/system/bt/Android.bp文件,其它的也类似。
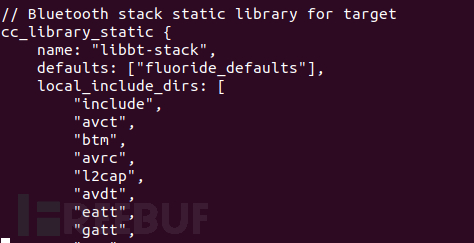
d)最后,使用codeql命令编译生成该模块的database。
codeql database create -l cpp -c "/home/ailei/android_source/build/soong/soong_ui.bash --make-mode libbt-stack" --source-root=/home/ailei/android_source/system/bt/ --working-dir=/home/ailei/android_source --overwrite ./android-bt-db
如下所示,生成的database文件夹为:android-bt-db。
![]()

4 CodeQL规则语法介绍
4.1 基础语法介绍
本节针对第3章的生成hello.c的database为例来介绍编写codeql的规则的语法。
1)下图为一个简单的codeql规则,目的是为了查找一个变量,其名称为buf。
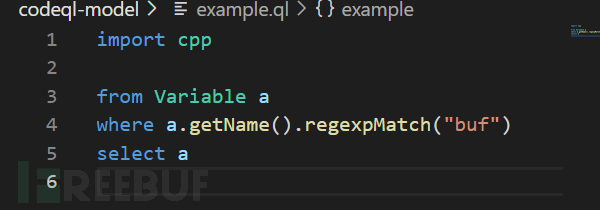
整个脚本的语法类似于数据库查询语句SQL,其包含4个部分:
import:表示要引入的类库,如cpp为引入针对c/c++语言的类库,java为针对java代码的类库等等。
from:定义数据的类型,可以定义多个,在这里定义了一个叫做“a”的变量,其中“Variable”就是它的数据类型,CodeQL中有很多数据类型,如fuction表示函数,functionCall表示调用函数等,可根据实际需求进行选择和使用。
where:进行查询时的条件判断,比如这里的语句表示“a”的名称的正则表达式为“buf”,即查找变量“buf”。
select:表示输出的结果,就是在运行完规则后,在结果展示栏里展示的东西,这里,我们需要展示该变量“a”在目标代码的名称。
该规则脚本写好后,就可以开始执行查询了。如下图所示。在工作区中写好的脚本处点击右键,在弹出的选择框中选择最下面的“CodeQL:Run Queries in Selected Files”,就会开始对之前选择好的database执行查询。隔一段时间后,查询结果会在右边结果栏处进行展示。
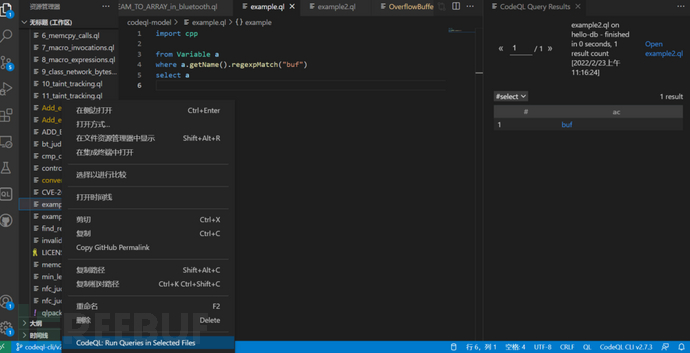
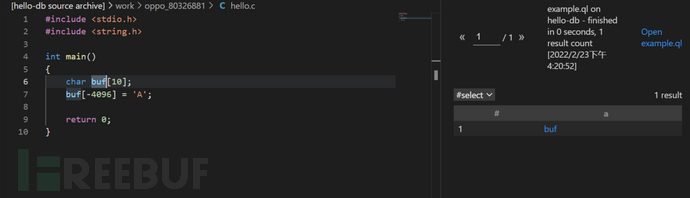
图中,右边结果栏中发现查找到了一个结果result:“buf”,可以对其进行点击,找到其代码位置,如下图。从而就获得到了buf变量的位置。
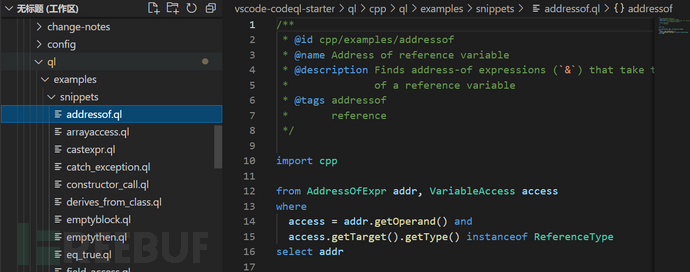
2)对前面规则文件的语法有了一个初步的了解后,可以学习一下现有的一些CodeQL规则的基础语法的例子,在2.1章节下载的vscode-codeql-starter目录下有一些规则文件可以学习,如图所示。具体目录可见于图中最上方。遇到不懂的语法可以使用网址[8]进行查询。如果能够成功看懂这些例子,那么CodeQL的基本语法就十分了解了。
4.2 进阶语法介绍
1)下图为vscode-codeql-starter目录下自带的一个已有CodeQL规则:OverflowBuffer.ql,用来检测缓冲区溢出漏洞,使用该规则对hello.c进行查询,能够找出其存在的漏洞。
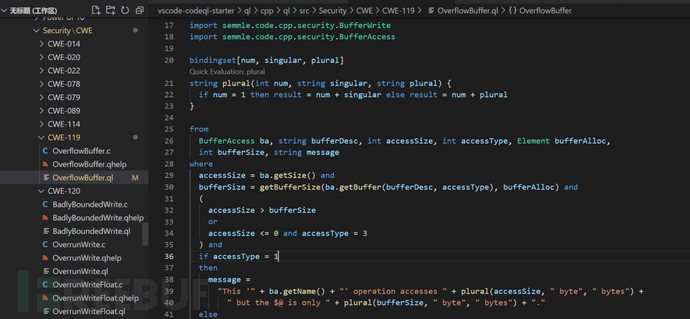
其中,string plural(int num, string singular, plural)是该CodeQL脚本文件中定义的函数,输入的参数num、singular、plural被bindingset指定其都是有界的,有界表示调用该函数时,传入的参数值是有界限的,更多的有界和无界的含义可以在[7]中搜索理解。该函数中的result是返回值,为string类型。
accessSize为调用buffer缓冲区的位置,其中getSize可以使用“Ctrl+左键”来查看它的含义。
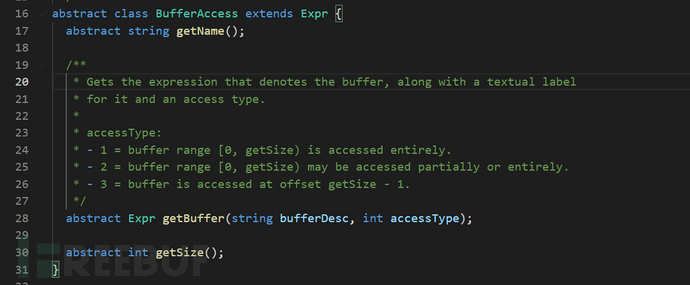
在该文件中,有许多的buffer处理函数继承BufferAccess,有“memcpy”、“strncpy”等,这表示符合这些特征的函数都会被查询。这里,我们主要看array数组的处理,如下图所示。
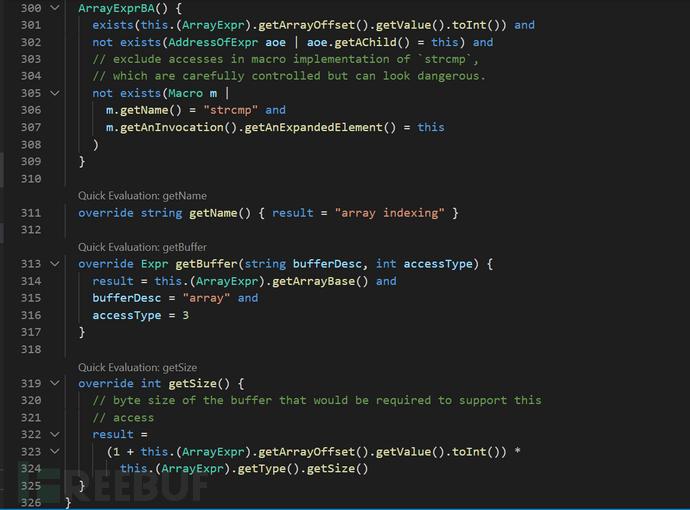
可以看到,getSize()的值为数组的index加上1,再乘以数组的类型大小。如本例中,buf[-4096] = 'A',中的getSize()的值为-4095,且其getBuffer()中,设置了bufferDesc为“array”以及accessType为3。
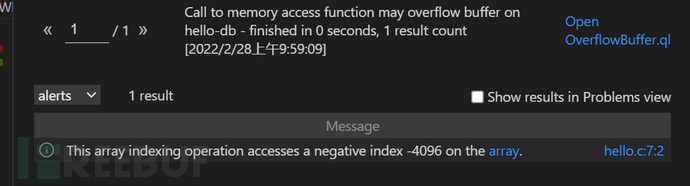
回到OverflowBuffer.ql,其30行的getBufferSize()获取buffer指针指向的buffer的分配大小,这里buf的值为10。因此,第34行的判断条件accessSize <= 0 and accessType = 3能够满足,表示存在漏洞。最后一个判断条件实际上是给message赋值用于查询结果输出。其中“$@”表示输出语句时获取select里面的最后一个参数值,这里为bufferDesc的值“array”。查询的结果如下。
2)污点分析。
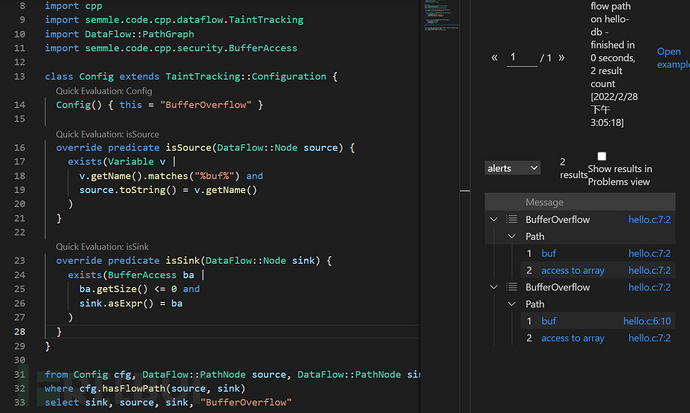
如上图所示,污点跟踪的基本语法包含有:
a)import semmle.code.cpp.dataflow.TaintTracking引入污点分析类库。
b)污点分析模板类:Config,这个class是一个模板类,使用污点分析就是填充该类中的isSource和isSink。表示从isSource到isSink存在污点传播路径。
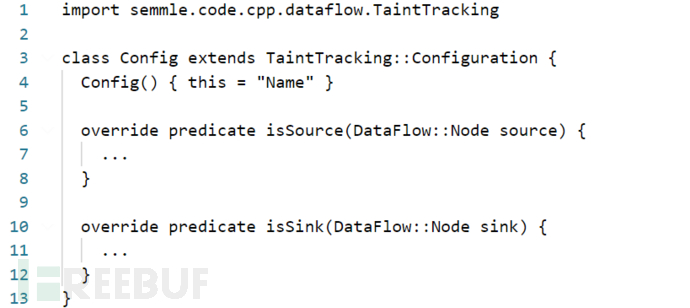
c)根据漏洞模型,提炼出Source和Sink,如这里针对hello.c写了个例子,Source为变量v,其名称带有“buf”。Sink为访问buffer的地方为负数或者0。可以看到该脚本有两个结果。一个都在hello.c的第7行,表示source和sink都在buf[-4096] = 'A';另一个结果的source在第6行,sink在第7行。即source为char buf[10]; sink为buf[-4096] = 'A'。这里只是举了个例子。在实际中用的话还需灵活修改。
学习CodeQL的规则语法也可以先学习github中的课程。其网址在[8],可以和本文进行对照,相信对CodeQL的使用有更深的理解,编写CodeQL规则也会更得心应手。
总结
CodeQL能够根据编写的规则文件,快速查询目标代码中是否存在符合该规则的代码段,这对于一些大型项目来说,极大提升了研究员使用代码审计进行漏洞挖掘的效率。随着越来越多的研究员使用该工具,可供学习的资料以及心得文章也会越来越多,不断地累积漏洞规则库,进行高效地挖掘漏洞,及时修复漏洞,能够为目标系统的安全保驾护航。
 Copyright © 2005-2021 网信安全世界版权所有
Copyright © 2005-2021 网信安全世界版权所有