

本期简单介绍数据安全领域必不可少的数据分类分级技术,这些技术一般在国标、行标中都会被提及到,如有谬误,恳请见谅。
01 数据分类分级概述
数据分类为信息安全管理提供了基础和指导。贯穿整个数据生命周期,它可以帮助企业制定正确的安全策略,采取有效的数据保护措施,不断提高数据安全水平,实现治理全面合规。
数据安全体系建设离不开数据分类【基石】。体现在以下几个方面:
指导数据安全策略制定。根据不同级别的数据分类,可以制定针对性的安全策略和措施。高风险数据要实施更加严格的访问控制、加密存储、数据备份等,低风险数据的安全策略相对简单一些。
优化资源分配。基于数据的风险等级分配相应的资源进行保护,如给高风险数据分配更多的存储空间或更高性能的服务器等。避免因分级不清导致资源浪费或分配不当。
引导用户的数据安全意识。通过公布数据分类分级政策,可以引导用户理解不同数据的敏感度和重要性,提高用户的数据安全意识,从而主动采取相应措施以保护数据安全。
支持数据生命周期管理。数据分类可以指导各级别数据的创建、使用、共享、归档和销毁等管理工作。如高风险数据应定期审计和更新,低风险数据可以定期归档或清理。
评估数据安全合规性。通过数据安全分类可以衡量目前的数据保护状况是否满足各类数据的安全需求,评估安全策略和措施是否到位,确保达到行业标准和法规的合规要求。
指导事件响应处置。数据泄露或丢失事件发生时,可以根据数据分类分级信息,正确评估风险,采取针对性的响应措施。高风险数据事件要优先处理,并上报管理层,低风险数据事件按一般程度处理。
02 数据分类技术
技术概述
敏感数据识别与分类分级是数据安全的核心内容,通过对不同类型的数据进行甄别,识别其中存在的敏感数据并对其进行分类定级处理,为针对性地对不同类别、不同级别的数据提供不同程度的安全防护提供依据。
“数据分类”围绕的是如何根据行业数据资源的属性或特征,将其按照一定的原则和方法进行区分和归类,并建立规范的分类体系和排列顺序;“数据分级”则围绕如何按照数据的重要程度对分类后的数据进行定级,从而为数据的开放和共享安全策略提供支撑。
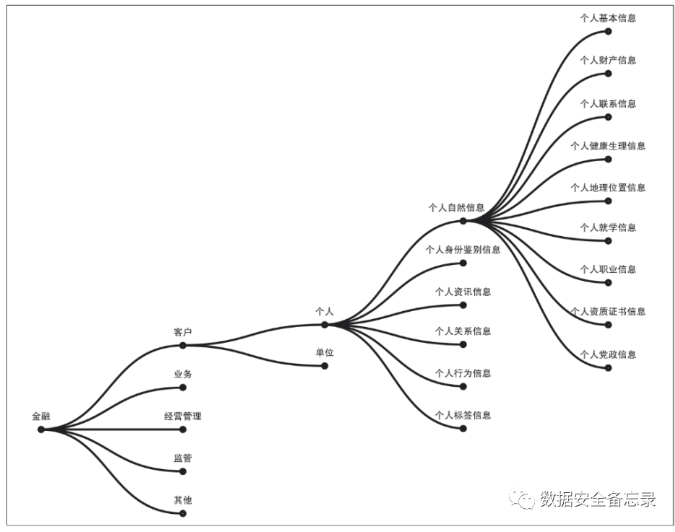
不同思路的数据分类技术
包括基于元数据类型的分类技术和基于实际应用场景的分类技术。
基于元数据类型的分类技术
内容感知分类方法
该方法依赖于对非结构化数据内容的自动分析来确定分类,其中涉及很多技术(正则表达式、完全匹配、部分或完整指纹识别、机器学习等)。如:手机号码、身份证号码、银行卡号码。
情景感知分类方法
该方法依赖于数据分类工具中能够被编码的现成的分类知识库,利用的是广泛的情景(上下文)属性,适用于静态数据(如基于存储路径或其他文件的元数据)、使用中的数据(如由CAD应用程序创建的数据)和传输中的数据(如基于IP的数据)。
基于实际应用场景的分类技术
标签库:根据分类规则建立标签库,可单独成静态库,或者直接在打标工具或系统后台进行自定义配置。可根据不同文件格式类型建立标签库,通过关键字、正则表达式设定标签规则。
结构化数据打标:用户建表时设置字段的标签,对底层数据表列权限进行控制,结合标签库规则/自定义规则,对列名、表名以细粒度进行数据分类划分。
非结构化数据打标:引入自然语言、数据挖掘等技术,对内容识别,与标签库特征进行匹配,对非结构化数据分类。
标注:对文档人工分类,作为训练集,用机器学习算法,经过学习,依据学习结果,对数据进行大批量打标。
训练:计算机从文档挖掘有效分类规则,生成分类器(规则集合)。
分类:将生成分类器应用于待分类的文档集合,获取文档分类结果。
技术路线
在数据分类技术当中,可以细分为“敏感数据识别”与“模板类目关联”。而“相似数据聚类”则作为前两者的补充。
敏感数据识别
敏感数据识别旨在发现海量数据中的重要数据,为后续数据分类分级奠定基础。
在技术层面,基于数据内容来进行识别。常用的敏感识别模型有以下几种。
正则表达式匹配模型
此类模型用于识别特征明显的敏感数据,如手机号、MAC地址等。
技术难点在于如何尽可能地兼容复杂情况。以手机号为例,是否以+86开始、是否包含各个电信运营商的最新号段、是否包含虚拟号等,都会影响敏感数据识别的最终效果。
字典匹配模型
此类模型用于识别国籍、民族等枚举字段。字典匹配的技术实现看似简单,但在实践中为了取得较高准确率,往往需要附加额外的逻辑。
以血型来举例,常见血型可以通过字典枚举A、B、O、AB等进行判断,但实际数据情况是:如果某字段内容仅包含3个字母:大量的A、B和少量的C,那么它极有可能只是在描述一个具有三种状态的枚举值(可能是被脱敏处理后得到的),而不是在描述血型。在这种情况下,需要我们在字典算法基础上嵌套一个合理的损失函数来进行训练,从而得到更为客观的置信度,最终判断该字段是否代表血型。
机器学习、命名实体识别模型
此类模型用于识别姓名、地址等包含文本信息的字段。
基于主题挖掘和文本分类、聚类等技术,可对大段文本信息进行识别和分类,如:合同、专利等;此外,添加相关的正则、字典,以及训练特定的智能分类模型,也可完成对指定数据内容的识别。
模板类目关联
在新的监管要求下,我们只有搞清楚了这个“地址”,将其明确划分为“用户身份数据-用户身份和标识信息-用户私密资料-用户私密信息”类别,并指定为3级数据,才真正意义上完成了对这一敏感数据的分类分级工作。

相似数据聚类
使用聚类算法:提供相似表、相似文件的聚类功能,辅助用户批量完成数据的分类分级。
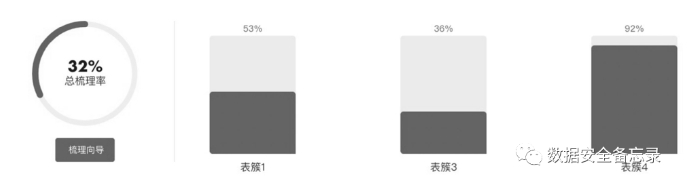
明确如何界定同一个表簇、同一个字段簇(彼此相似的字段组成的簇),在此基础上如何给向导辅助用户按照某个顺序来进行手动分类分级。
03
数据分级技术
分级指的是在分类的基础上,依据数据的敏感程度、影响范围及自身的价值等对数据进行等级划分;依据分类产生的标签结果,可根据标签定义数据的敏感程度,对数据进行进一步分级。

本文摘取来源:《数据安全领域指南》
 Copyright © 2005-2021 网信安全世界版权所有
Copyright © 2005-2021 网信安全世界版权所有