

一、背景介绍
这是一个运行了2年的个人小项目,最近目标网站改为扫码登录,于是公布出来作为技术分享。项目缘起是女神参与的签到活动,坚持了很久,后来嫌麻烦,中途放弃又觉得可惜,问我能不能实现程序自动登录+签到。我打开某网站看了下,python+selenium就可以实现,但人家要的是全自动,这就需要把验证码自动识别的难点攻克掉了。懒永远是技术进步的源动力啊,不过我对机器视觉本身也比较感兴趣,那些年小区和单位的门口都是车牌识别了,也想借此机会探究一下这门技术是怎么回事。
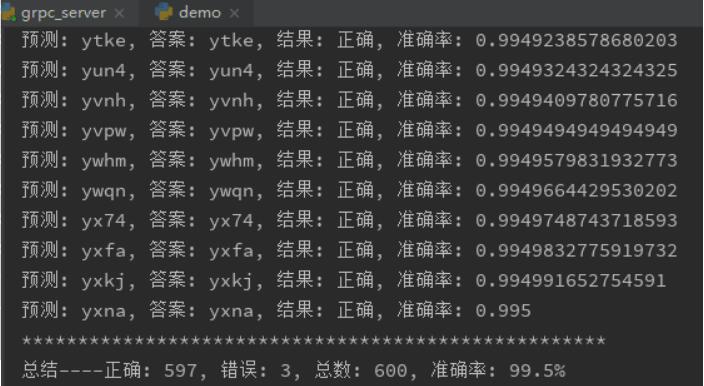
先上两张镇楼图,一张是准确率统计,一张是实战截图。其中动图只进行了验证码识别,没有登录操作,仅用于效果展示。本文不会对技术细节及理论原理做太多介绍,只是展示一下听起来高大上的人工智能+机器学习+计算机视觉,个人也有很多场景可以把玩的。如果对这个效果感兴趣,可以接着往下看看:
二、分析验证码:
某网站的验证码还是挺复杂的,有四套模版,有的加了干扰线,有的是用点阵构建字母,有的进行的各种扭曲,还渲染上了七彩色。
先去网上看看有没有现成的轮子,方法很多,简单的方法能实现,就不用麻烦的。
1、先试试谷歌的tesseract、pytesser3,都是一回事,代码极其简洁,两三行就出结果,勉强可以接受吧,规规矩矩的字,识别率还挺高,但稍加变形,结果就驴唇不对马嘴。
2、本着一切从简的原则,还是打算依赖pytesser3,给它喂适合的数据,把验证码转灰度图、二值化、滤波降噪、模糊各种手段组合着用,还测试了4位验证码切割成4张小图片,以单字符识别的形式提高它的准确率。不过不论你用什么手段往它身上招呼,识别效果都差得远着呢。
3、只有祭出终极大招了,机器深度学习+卷积神经网络,在入这个坑之前,做了好久好久的心理建设,cnn这么大的坑我爬得出来嘛?经过了一个多星期的学习,跑出了镇楼图的效果,也稳定运行2年时间,可以简单分享一下大致调试过程了。
三、开发调试流程
cnn模型训练需要有训练集和测试集,这两个数据集,计算机需要知道答案,那么知道答案的数据怎么来?
1、先写个脚本,采集了200份目标网站的验证码,人工打上标签,把答案作为验证码图片的文件名前4个字符。
2、人肉打标效率太低。花钱打标?不至于吧,自己写个小程序签到玩,还要投资?那就自己生成一批吧。观察目标网站的验证码,扭曲、模糊、加线的手法挺像谷歌开源验证码开发包的,下一个回来,模拟一下。包是java的,在eclipse里略做改动,一顿午饭的时间就生成了50万张带答案的验证码。类似这样,文件名前4个字符就是答案。
3、训练集有了,下面搭建训练和部署环境,基于简便和通用性考虑,这次验证码图片不再切割,整体丢给机器去训练。
四、验证效果
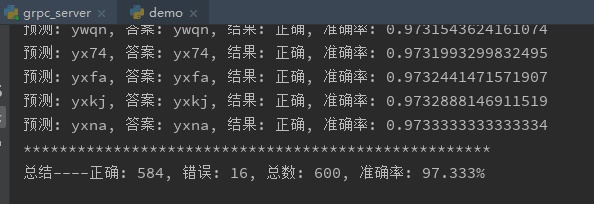
到了收获的时候。程序调好,临近下班,把训练集和测试集丢给程序,6W数据CPU要跑一晚上,GPU只用20分钟。我这50W数据,GPU半个晚上也就训练完了。下面是第二天早上,实验环境下的数据,实验环境是指:训练集,测试集,考试集都是用同一套系统生成的。准确率达到97.3%。
那么在实际环境中,效果如何呢?实际环境是指训练集,测试集是通过自己写的代码生成的。而考试集是从目标网站采集回来并人工标识的。
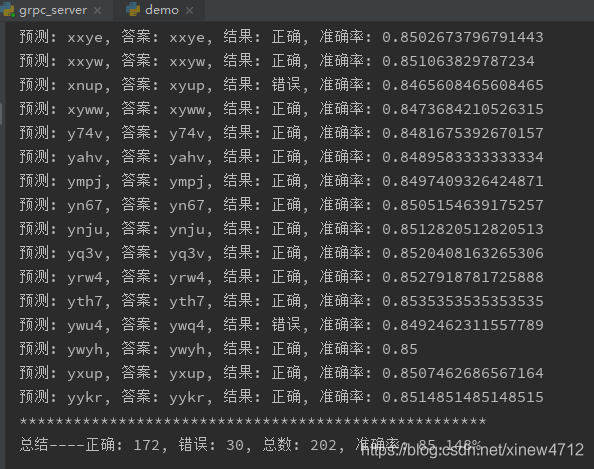
真实环境才85%,有点低了对不对?把错误的地方都找出来查找一下原因:
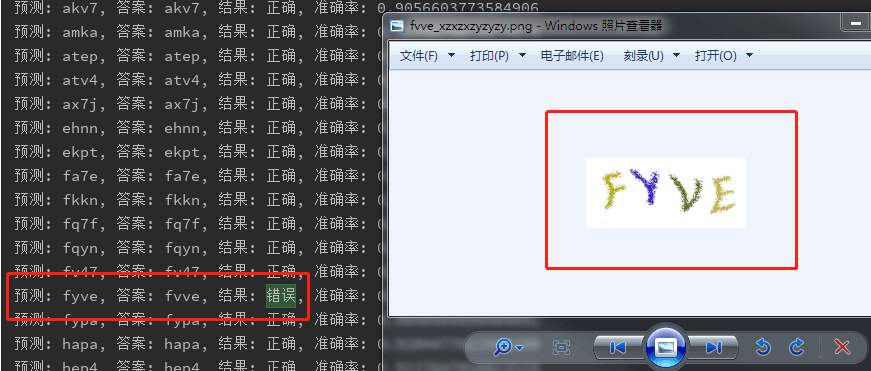
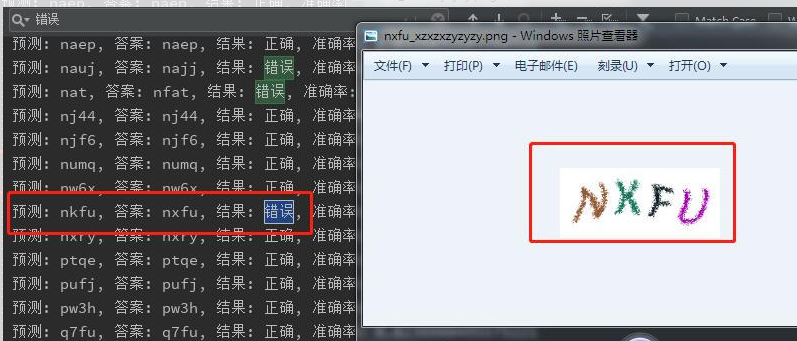
类似这样的错误,是我识别错了,机器给我指出了答案的不正确,让我自愧不如啊。不过这感觉挺美妙的。
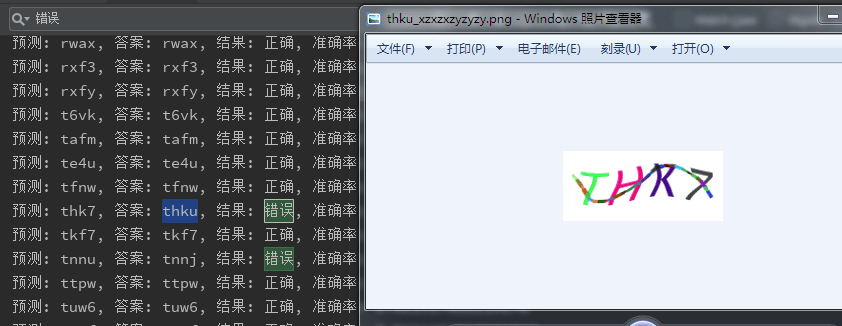
还有这种的,这么明显,怎么可能人肉识别错呢,后来一看键盘,7和U离得太近,一定手滑了。排除这些人工标识出错,真实环境的准确率达到90%。基本能符合自动登录的要求了。
五、如何提高准确率
后来我进一步思考,还有没有什么办法可以让准确率更高一些呢?实验环境和真实环境差在哪里,有7%的差距呢?目标网站一定是有哪些微调我没有观察到。比如这张:
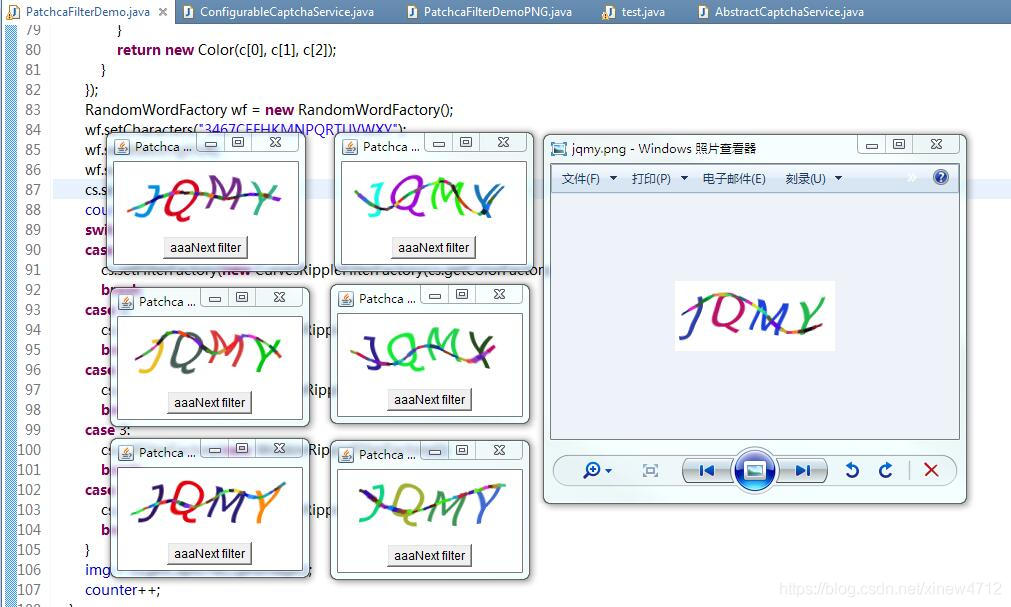
左边六张图是模拟生成的验证码,右边一张图是人肉从目标网站上打来的码。肉眼看上去很像,字体上似乎有微小的差别,导致了实验环境与真实环境7%的准确率误差,要解决这个问题,有两个办法:
1、人肉打出足够多的码,以此为测试集,重新训练。效果应该不错,可是缺点也显而易见,哪有那么多功夫去人肉打码。或者有时间,就是懒,你要用技术去解决啊。这么一说,好像也有办法,Apple 的AI首秀就是治这种懒的,见办法2。
2、关键字:simgan。认真研究了相关的2篇论文,觉得有搞头啊,决定试一下。
六、提高准确率的进阶实验
又经过十几天的实验(训练一次太久了),对simgan原理有了更深的了解,SimGAN-Captcha的实验也完全复现,然后对其进行扩展,应用到自己的环境中进行样本增强,实验过程按这样的思路:
首先复现SimGAN-Captcha过程。然后改灰度图为RGB,通过无标识的真实数据和有标识的模拟数据,训练SimGAN-Captcha,通过训练好的模型,Refine上面提到的50万+1万模拟的训练数据,通过Refined的数据,重新训练验证码识别模型,统计准确率做对比。可是效果并不好,甚至肉眼放大也无法在像素层面上找到差异,可以说模拟的很逼真,也可以说Refine没效果。甚至让人怀疑,SimGAN-Captcha是否工作了。于是用另一套验证码生成器生成完全不相同的验证码,让SimGAN-Captcha在像素层面对新验证码进行强化,用以证明Refine确实是干活了。
经过了50多小时的训练,SimGAN-Captcha有了明显的增强效果,举个例子:
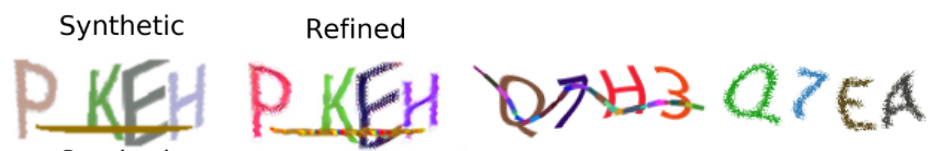
为了方便表述,从左到右我们依次叫它们1号、2号、3号、4号。1号是用完全不同的算法X生成的验证码,灰头土脸的。3号、4号是上文提到的目标网站的真实的不同形式的验证码。以算法X生成的类1号验证码为Synthetic数据集,以类似3号、类似4号验证码为real数据集,refine出来的合成验证码为2号。仔细观察2号,已经有了很多3、4号的特征,比如:1、不再灰头土脸,变得鲜艳了,P,K,H色彩对比都比较明显;2、干扰线有了彩色断点,这个特征很好的模拟了类3号样本;3、字母P与E有了类4号的点阵效果,模拟点阵应该是SimGAN的拿手好戏,如果让它把干扰线变扭曲就难为它了。
看来SimGAN的确有效果,它能在像素层面上,把模拟样本尽量向着真实样本的方向改造,不过,即使改造的“像一些”了,好像对准确率的提高也没多大帮助。用谷歌的captcha生成的验证码做Synthetic数据集,目标网站验证码做real数据集,进行训练,然后用这样的模型生成cnn的训练集与测试集,再对目标网站的验证码进行测试,准确率提高不到0.5%。用上面提到的算法X生成的验证码做Synthetic数据集,目标网站验证码做real数据集进行训练,然后用这样的模型生成cnn的训练集与测试集训练cnn,与直接用X算法生成的训练集与测试训练出的cnn模型,在正确率的对比上,只提高0.1%。把上面的过程用语言描述出来,都已经很绕了,实际训练时,尽量安排在晚上或周末,累计在训练上花了4、5百小时,花了这么大的时间成本,取得这么小的进步,确有不值。而当我走了一大圈,回到起点,试着把cnn的训练加强,对它提高要求,不以准确率达到99%为中止条件,要准确率达到200%才停止训练(类似while 1 循环),只用了一顿午饭的时间,准确率就有了2.2%的提升。用同样的600份实验数据做对比,上篇文章中准确率是97.33%,这次提高到99.5%,如镇楼图。对于验证码识别来说,在正确的道路上努力训练才是王道,SimGAN并没有那么好的效果。
SimGAN应该是有自己擅长的领域的,验证码增强不行,图像增强会不会效果不错?前文提到的苹果AI首秀的那篇论文,对眼球控制的图像进行样本增强,似乎效果显著啊,我也完成了复现,效果非常好,有机会再分享吧。
 Copyright © 2005-2021 网信安全世界版权所有
Copyright © 2005-2021 网信安全世界版权所有